I’m currently benchmarking multi-node serving performance with vLLM, specifically looking at the impact of enabling or disabling RDMA (including GPUDirect RDMA).
My setup consists of two nodes, each with a single 40GB A100 GPU.
I’m controlling the RDMA settings using NCCL environment variables.Initially, I encountered a log message, NCCL INFO GPU Direct RDMA Disabled for GPU 1 / HCA 1 (distance 8 > 5). To resolve this, I explicitly set NCCL_NET_GDR_LEVEL=10.
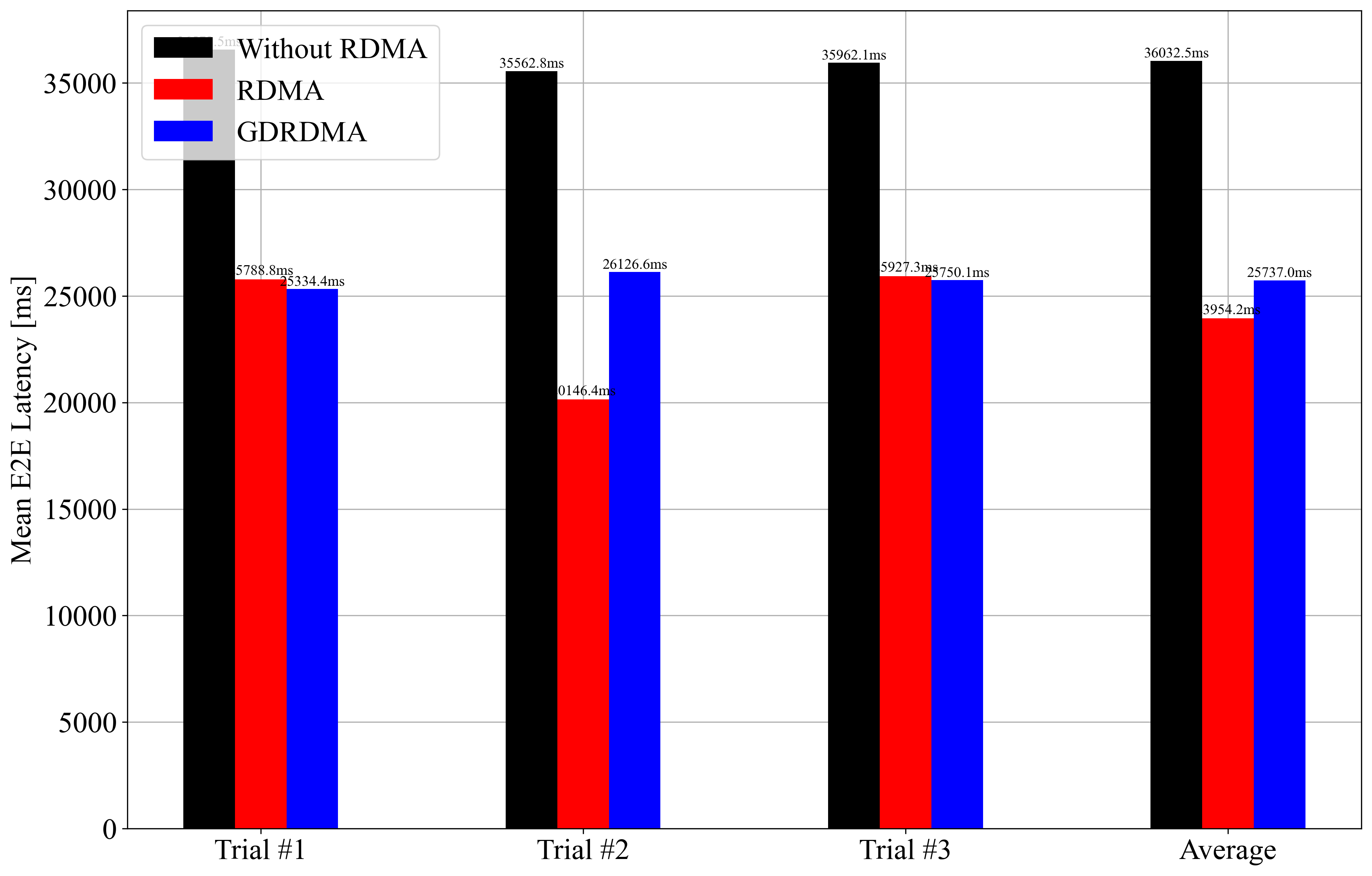
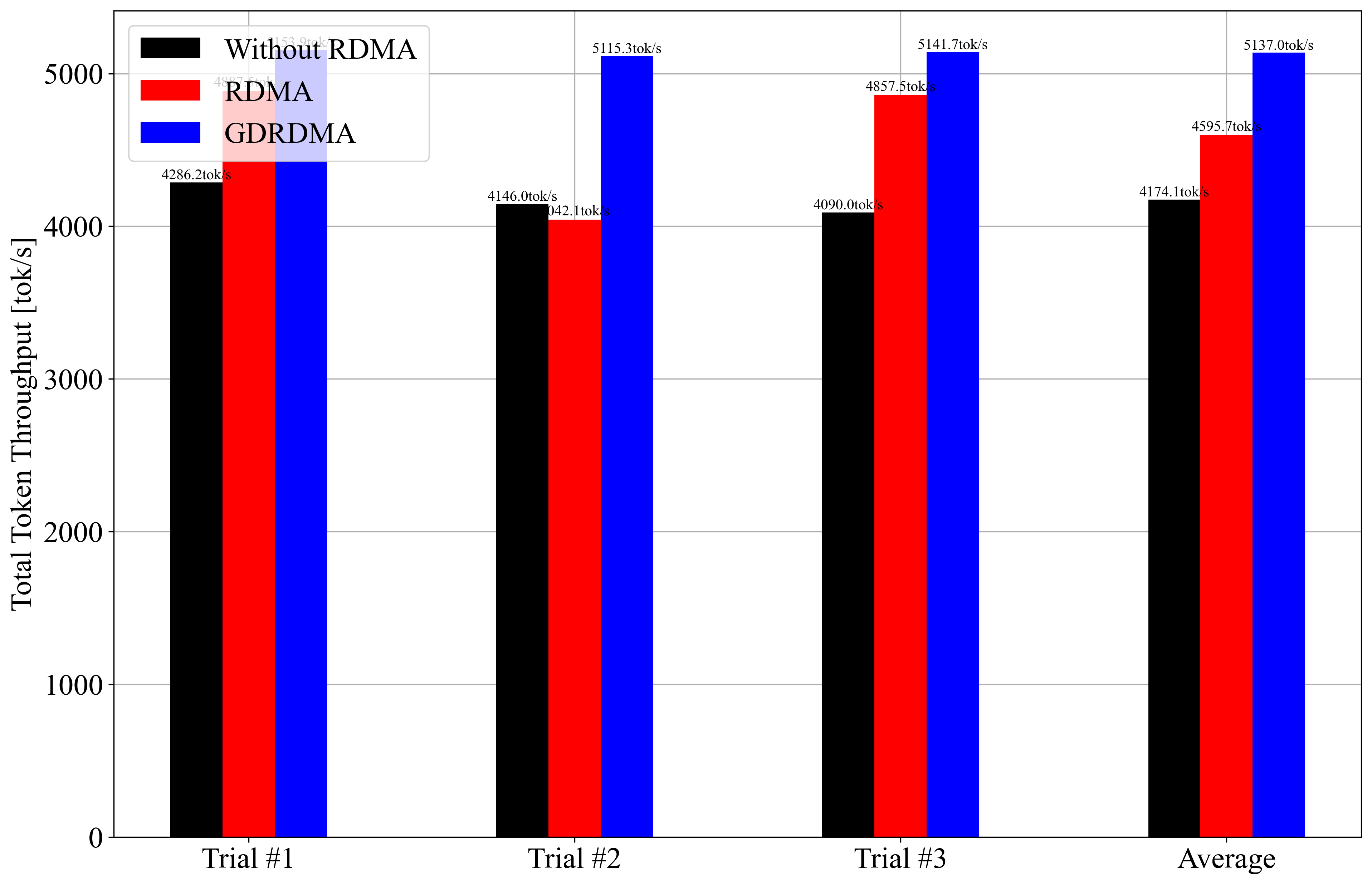
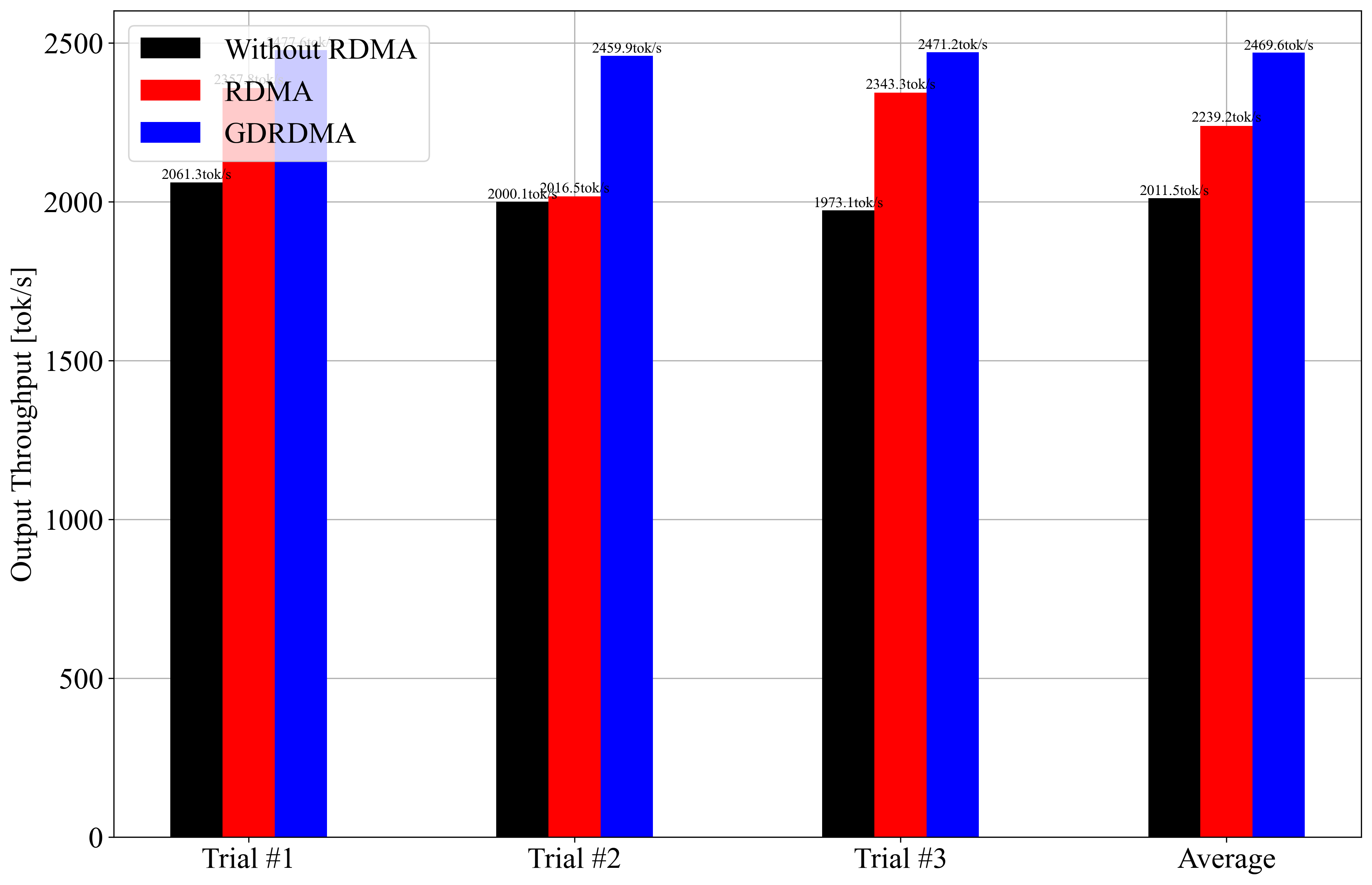
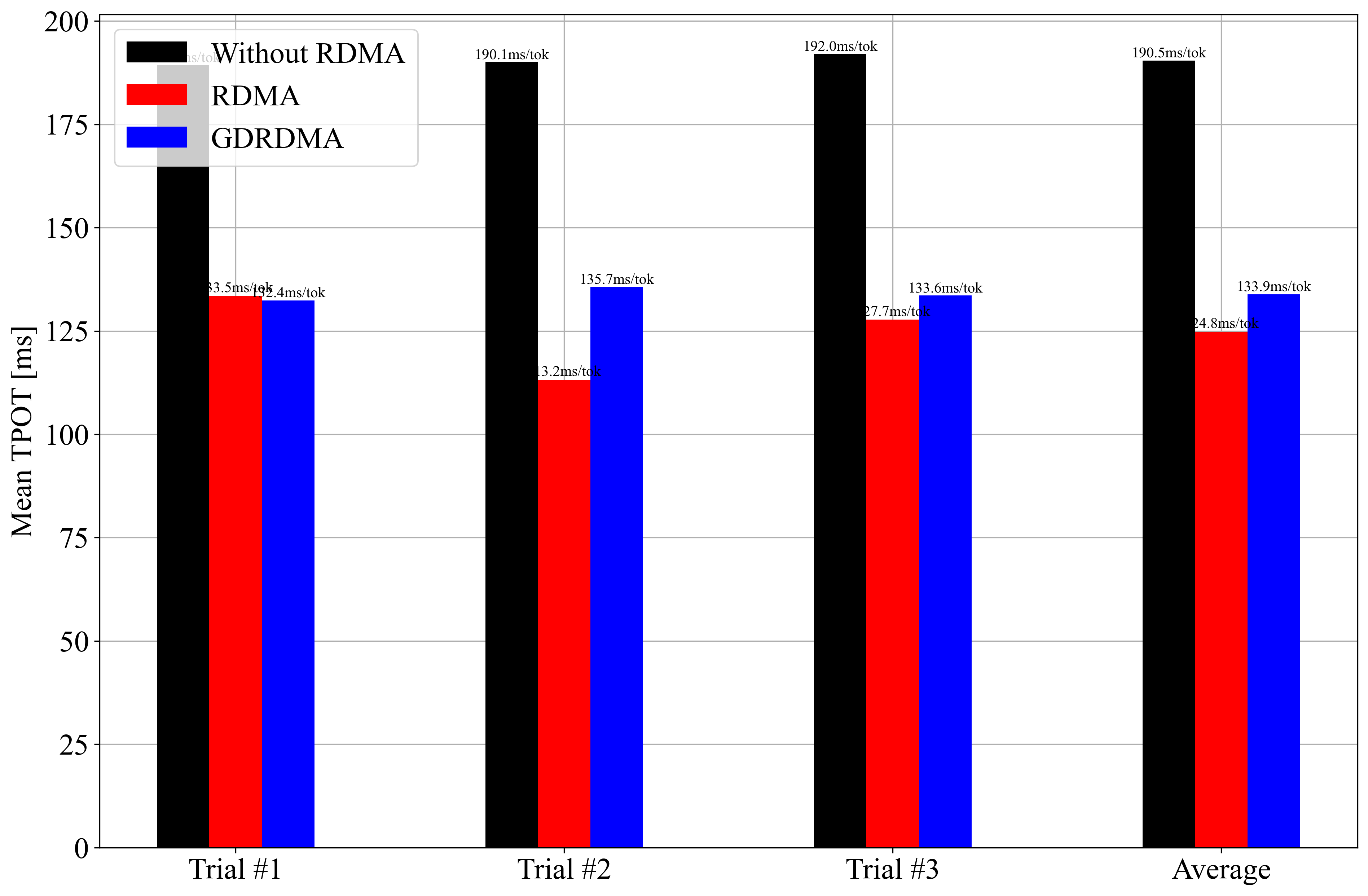
However, after running the benchmark (vllm bench serve), I’ve observed that the performance difference between using RDMA and not using it is not as significant as I expected.
Could anyone share some insights or potential reasons for this observation? Any thoughts would be greatly appreciated.
Your results are consistent with recent vLLM benchmarks: enabling RDMA (and especially GPUDirect RDMA) does improve throughput and latency, but the gains are often modest for small-scale setups (e.g., 2 nodes, 1 GPU each, TP=1, PP=2). The largest benefits from RDMA/GDRDMA are seen in large tensor-parallel (TP) deployments, where inter-node communication is the main bottleneck. In pipeline-parallel (PP) or small TP setups, communication overhead is lower, so the impact of RDMA is less pronounced. Your bar charts show GDRDMA consistently outperforms the other modes, but the absolute difference is not dramatic—this matches published vLLM findings for similar configurations (see here, and here).
Potential reasons for limited RDMA benefit in your case include: (1) with only 1 GPU per node and TP=1, most computation is local, so little data is sent over the network; (2) pipeline parallelism (PP=2) introduces some communication, but not enough to saturate the network; (3) the model size and batch size may not be large enough to make network transfer a bottleneck; (4) other system factors (disk, CPU, or software overhead) may dominate. For maximum RDMA benefit, try larger TP (multiple GPUs per node), higher batch sizes, or models with heavier inter-node communication (source, source).
Would you like a step-by-step breakdown of how to further optimize or test your setup?