Hi team,
I’m new here and reading the PagedAttention part, of the latest vLLM code. And when it comes to the PagedAttention.split_kv_cache method, I find something doubt.
class PagedAttention:
@staticmethod
def split_kv_cache(
kv_cache: torch.Tensor,
num_kv_heads: int,
head_size: int,
) -> Tuple[torch.Tensor, torch.Tensor]:
x = 16 // kv_cache.element_size()
num_blocks = kv_cache.shape[1]
key_cache = kv_cache[0]
key_cache = key_cache.view(num_blocks, num_kv_heads, head_size // x,
-1, x)
value_cache = kv_cache[1]
value_cache = value_cache.view(num_blocks, num_kv_heads, head_size, -1)
return key_cache, value_cache
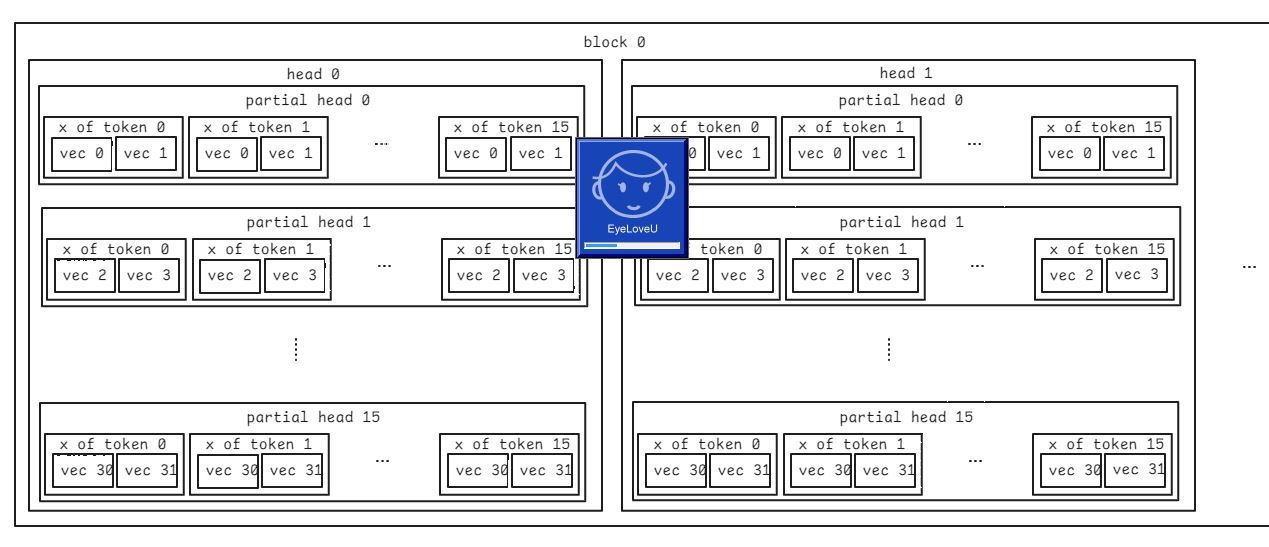
In this method, the input kv_cache seems have a shape of [2, num_blocks, block_size, num_kv_heads, head_size].
And the target key_cache result is a shape of [num_blocks, num_kv_heads, head_size/x, block_size, x].
Is that correct to reshape the kv_cache by
key_cache = key_cache[0].view(num_blocks, num_kv_heads, head_size // x, -1, x)
rather than
key_cache = key_cache[0].view(num_blocks, -1, num_kv_heads, head_size // x, x).permute(0, 2, 3, 1, 4)?
I do think they are different, and the latter seems a formally correct reshaping. Wish someone can help me out.