Hey vLLM team. Congratulations on the new release! Was looking forward to it for quite some time (was using torch 2.8 for our RL trainer so needed 2 venvs, one running torch 2.7 until the new release).
However, it seems that upgrading to the new version is yielding worse reward curves in our CI.
I was wondering if you guys have any ideas as to why this could be the case? Our suspicion right now is that there were significant changes to the sampler.
Previously, we patched around the old exporting logprobs logic with a custom sampler that exported them after temperature scaling. It seems that this isn’t needed in version 0.10.2 with the logic now changed to export the processed logprobs in the topktopp sampler class after temperature scaling and truncation filtering (topk, topp). I think the change in reward is unrelated to the new logprobs being after topktopp filtering as modifying the code to export the logprobs before that didnt seem to make a difference to the reward curves.
If you guys would like to repro, you can run uv run pytest tests/integration/test_rl.py -m gpu in the main branch and the PR branch up-vllm-version in prime-rl. This should take ~6m on 2x3090 and ~5m on 2 xH100. The test will export to ur wandb with the project ci-reverse-text-rl-local.
It seems likely that the reward degradation after upgrading vLLM is related to changes in how logprobs are computed and exported in the new version. According to the discussion in PrimeIntellect-ai/prime-rl#919, vLLM 0.10.2 now exports processed logprobs after temperature scaling and top-k/top-p filtering, which aligns with your previous custom patch. However, your experiments suggest that exporting logprobs before or after top-k/top-p filtering does not explain the reward drop, so the root cause may lie elsewhere in the sampler or numerical differences in logprob computation.
My understanding is that vLLM logprobs can vary due to numerical instability or batching differences, especially after major changes to the sampler or logprob export logic. This is supported by reports of logprob instability and numerical differences in vLLM compared to HuggingFace Transformers, which can affect RL reward scaling and convergence (discuss.vllm.ai: numerical difference between vllm logprobs and huggingface logprobs). You may want to check for subtle changes in logprob values, sampling order, or batch handling between versions, as these can impact RL reward curves even if the logprob export location is unchanged.
Would you like a step-by-step breakdown of how to compare logprobs and sampler behavior between vLLM versions to help isolate the cause?
Yes, the PR changes the definition of “processed logprobs.” In vLLM 0.10.2, “processed logprobs” are now computed after applying all logit processors, including temperature, penalties, and top-k/top-p filtering, rather than at an earlier stage. This change can affect downstream RL reward calculations, as the logprobs now reflect the final sampling distribution, not just temperature-scaled logits (see comment).
If your RL pipeline expects logprobs before certain processors, this semantic shift could impact reward scaling and convergence. Would you like a detailed breakdown of the logprobs computation order in the new vLLM version?
The extra argmax_invariant and topptopk dont seem to be the cause of the issue. I tried to export the logprobs right after the temp scaling and obtained the same reward curve.
Modification to the sampler to make export happen right after temp scaling:
Reward curve is similar to the original PR which bumped the version:
Your experiment confirms that exporting logprobs immediately after temperature scaling (before argmax_invariant and topk/topp) yields reward curves nearly identical to exporting after all processing steps. This suggests that the extra argmax_invariant and topk/topp steps are not the cause of the observed reward differences between vLLM versions (see your comment).
The reward curve similarity indicates that the main source of change is likely elsewhere—possibly in subtle numerical or sampler logic differences introduced by the vLLM upgrade, not in the logprob export location. Would you like a step-by-step guide to further isolate the source of the reward curve change?
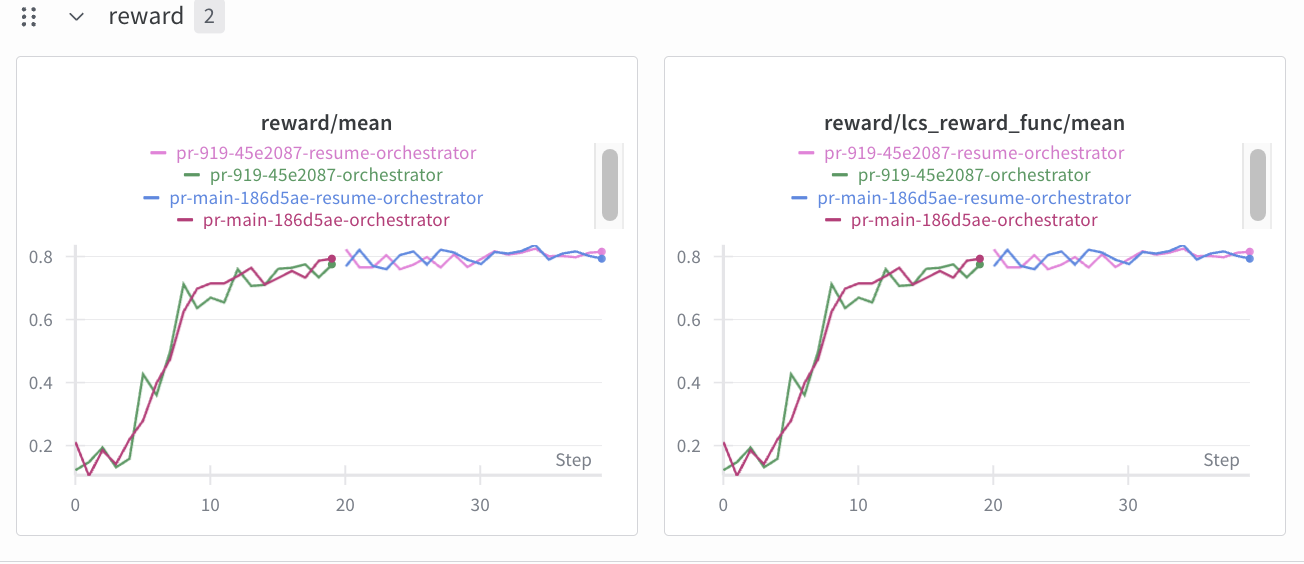
Ah this turned out to be an issue with our trainer in the checkpoint loading logic we use for torch 2.8 and was unrelated to the vLLM version bump. Sorry for the false alarm guys.
Commenting out the bad checkpoint loading logic fixes the rewards
Thanks for the update! Since the reward curves are now similar across all configurations and the issue was traced to your trainer’s checkpoint loading logic (not the vLLM version), there is no vLLM-related problem here. Commenting out the problematic checkpoint logic resolves the reward discrepancy, as shown in your attached graphs.
If you need further help with vLLM or RL integration, let me know!